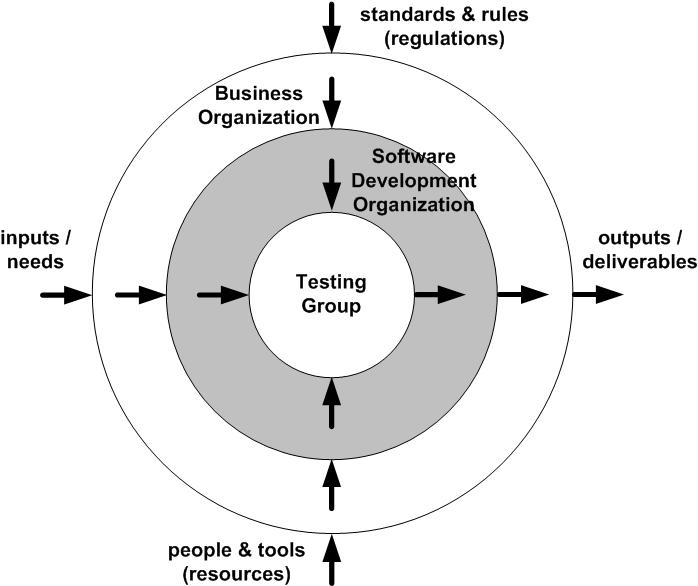
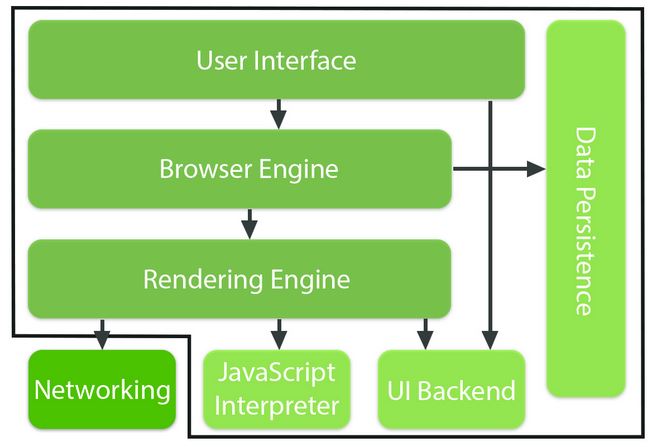
I recently interviewed Melissa Tondi on the topic of mobile testing. Melissa is the founder of Denver Mobile and Quality (DMAQ), Head of QA at ShopAtHome.com and has had significant experience working in, and speaking publicly about, mobile testing. We wanted to share that conversation with you.
Mobile Testing
Christin: What made you interested in mobile testing? How did you end up working in that space at all?
Melissa: About 6 years ago, when I was head of a large global QA team, our company had the edict of mobile first. From our CTO down, we knew we needed to be ahead of the curve around mobile. I, and many people 5-6 years ago, didn’t have a great strategy to get started.
We put a lot of effort into making sure we didn’t repeat the type of mistakes that often come with introducing disruptors and new technologies into large organizations. The biggest problem we were trying to solve was: how to implement the type of testing that mobile needed without necessarily increasing staff while on a minimal budget. Most importantly, how do we become as efficient and productive as possible as quickly as possible, while introducing this new disruptive technology into an existing QA team?
This was a really big challenge and we had to solve it for global teams in a dozen or so more offices. I was challenged to create a strategy that didn’t just work locally. It had to be able to scale up enterprise-wide. Once we did that, we deemed ourselves successful. I really enjoyed the challenge of doing that.
About 3 years ago, I was offered a position to manage a mobile specific team. With the knowledge I had gained, I was able to build something more solid and scalable from the ground up. That challenge peaked my interest and I have been doing that ever since.
Creating a Competitive Edge
Christin: 6 years ago, you must have been still really pioneering mobile testing?
Melissa: It was something, it really was. We were a technology company and really needed to be on the cutting edge of what was happening and what our users were looking for. We had a user base of about 60 Million users globally, primarily US- and North American-based, but we saw the trends of where mobile was taking us. We knew we needed to come in here.
As far as being a pioneer, there were pioneers before me, but we were able to create a big case study on mobile. The early adopters on our platform had as seamless a mobile experience as could be had at that time.
Christin: You must have created a competitive edge for that company. Do you feel other companies have caught up by now?
Melissa: When I talk about this at a public forum or in a consultation setting, I divide companies into three categories. One are the innovators, the bleeding edge, cutting edge technologists, who would be in the top ten disruptors of technology and are creating technology to be consumed by the second tier which I call mainstream companies. This is mainly where most of us have worked. They are often early adopters, the first to consume the new technology. The other companies may be slower adopters of technology.
We were really straddling between the top tier creators and straddling very early mainstream adopters, with mobile especially.
Fast forward from 6 years ago when I first got my feet wet in mobile technology and testing, fast forward to 2-3 years ago, companies were adapting the mobile first mandate or edict, but I’ve seen lower adoption rates in the mainstream companies than I would have thought. I am also a surprised with the slower adoption of mobile testing and the building of testing strategies around that. I think we should be further ahead in the mainstream companies than where we are today, just based on conversations with co-workers and people in the industry.
Security, Performance, and Accessibility Testing
Christin: One thing I am really curious about is security in mobile. Companies seem very willing to take a lot of risks around mobile testing. Where do you think we are at with that?
Melissa: I agree with that. In that large organization I was running, around that timeframe or a year or two before that, security testing from a functional standpoint was unheard of. We treated any security testing as something not in our domain of expertise. It was almost something we shied away from, and threw it over the wall for the ethical hackers that were part of the company but had very little interaction with the agile team.
So we got a head start on the functional security testing. I really feel strongly about the organization OWASP. They publish a top ten testing guide, top ten vulnerabilities and several of those top ten are things we can bring into the functional testing team. So I am a big proponent of aligning with OWASP where applicable, bringing in some of that security testing that we shied away from in the past.
One of the keys we should be really paying attention to, from a mobile security testing standpoint, is really understanding how PII data, Personally Identifiable Information, how that flows from user input and how that actually posts to the backend.
We can bring a lot of emphasis to PII in the early round of testing. Making sure it meets the criteria for any regulatory boards or any type of auditing perspective. And then, there is also the alignment with OWASP on techniques on how to actually test that data through.
Christin: There is frequently a big gap between functional testing and other areas. I would say security is a big one, and performance testing. I am surprised that we, as testers, are so fast to dismiss that as something as not our area of responsibility.
Melissa: A week or so ago I did a presentation, “Shifting the Test Role Pendulum”. I identify three major areas that we have thrown over the fence for the lack of a better term. Performance, security and accessibility testing are the three areas I feel we do a bit of a disservice. Where we either don’t put emphasis on them in the functional testing team, or we simply don’t address them at all.
You are right, we have shied away from that, saying this isn’t our responsibility, not my expertise or I don’t know how to do performance testing. Performance testing is one of those ambiguous terms and a catchall phrase for how the user experience is going to be under load or in concurrency. There are a lot of tests that we can bring into the functional testing team and for those companies that are practicing agile, within those agile teams.
Balancing Manual Testing vs. Automation
Christin: What do people ask you the most when you are talking about mobile testing at a conference or working at an organization? What is the top concern?
Melissa: I am torn between two. I think the biggest one is: what is the proper balance of testing on virtual vs. physical devices?
One camp says: physical devices all of the time, 100%, because that is what is guaranteeing the user’s experience. This means securing and maintaining physical devices. You also have a lot of manual testing. The other camp that says: all or almost everything is tested against simulators or emulators, using the SDK’s on the platforms that the developers are using.
I think that is the biggest one, because you really do see camps that are one or the other. They are either saying 100% on physical or mostly all on virtual devices. Then I come and say, “No actually there can be a nice balance of both. You don’t have to just do one or the other.” It is more designing the strategy so you understand what the important tests are going to be and overlay that with how, or where, you are going to test them.
Christin: Testing on real devices, means more manual testing. Do you find organizations that do more test automation, in general, are more biased towards using simulators or emulators? And organizations that have more manual testers are more focused on real devices?
Melissa: I would say that’s a good way to categorize it. There are a lot of cool automated tools out there and, as technology increases, we will see more companies starting to invest in solutions around automation. I have made this statement many, many times: we really need to look at automation as making the exploratory or human-based testing more efficient instead of trying to have a silver bullet solution.
In the Future
Christin: What is next for you, where do you see yourself in 5 years? Do you see yourself in the mobile sphere, or are there any particular technologies you would like to have a chance to work on?
Melissa: I am very interested in artificial intelligence (AI) that is coming in and 3D technologies and enhancing the user experience is something I’d love to get into.
I would hope that mobile is not as much of a disruptor in 5 years, as it is now and we embrace it and it becomes just another service that is offered within all of our functional testing teams. We look at it as we would any type of technology, that there is upfront education and training and skill development around it and, if you have a proper overall test strategy in place within your department and infrastructure that supports scaling out technology disruptors, that mobile just becomes another one of those service offerings.
I am pretty passionate, and I certainly love working with companies and consulting with companies and working with their overall test strategy first. In 5 years, I see myself still advising and speaking on that same platform and hopefully mobile becomes mainstream and maybe becomes an afterthought because everyone would have adopted good strategies to begin with.
If a team or company has a good strategy in place to scale and adopt new technology, the actual technology they are adopting becomes secondary. The first part and primary portion is that there is a good infrastructure in leadership and a good balance of technical skills in place, then the technology comes in.
Christin: Thank you for your time Melissa, it has been very interesting talking to you and have raised a lot of ideas in my head.
Melissa: No problem, my pleasure. I always enjoy talking to you and love what you guys are doing over at PQA.
See Melissa’s presentation, “Shifting the Test Role Pendulum“



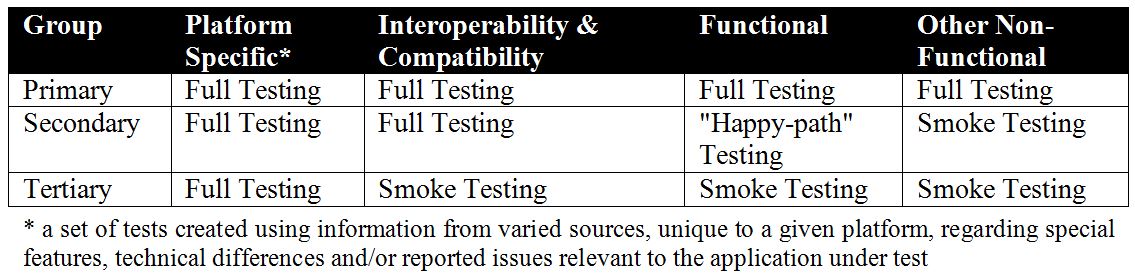
 As often an outsider to a new client’s business, I feel one of the most significant first steps is to rapidly integrate with the mindset of the client’s teams and to “get immersed in their world”.
As often an outsider to a new client’s business, I feel one of the most significant first steps is to rapidly integrate with the mindset of the client’s teams and to “get immersed in their world”.