

Friday afternoon I was looking through the latest tweets when my eye was caught by the phrase Dendogram-Based Testing. I like all words that have a Greek origin and sound like science, so I had a closer look, and of course it was James Bach introducing a new concept. One that – as far as I understand – is still pretty much missing a definition. No reason to let a small detail like that stop you, right?
After reading up on dendograms I realized that I have actually used them before, but didn’t know they were called dendograms. A dendogram is basically a way to take data points and cluster them based on their properties. They are commonly used in computational biology, and that’s were I encountered them. About a year ago I spent a week of my vacation making dendograms from genome data.
In testing, one way to use dendograms would be to cluster defects. In order to do this you would need to define a set of properties for each defect, and based on these properties it would be possible to calculate distances between the defects and cluster them in a dendogram. I will save the discussion on whether this is useful or not for later.
Example: The android game SuperTester
To the best of my knowledge this game does not exist, but if it did it would be a game in which the player has to find critical bugs in imaginary applications under time pressure. Just for the record, I haven’t thought too much about this so I’m just making it up as I go along.
Let’s say five bugs have been found when testing the actual SuperTester game:
1. Can’t save game (D1)
2. Can’t change sound volume (D2)
3. It is possible to register the same bug twice (D3)
4. Application crahses if you find exactly 13 bugs (D4)
5. Application crashes if you play for more than 59 minutes and 59 seconds (D5)
Now we need to assign these defects properties in order to cluster them. This is the tricky part and requires some careful thinking, Which properties you pick decide what information you will get out of the dendogram. For now I’m just going to pick two properties for the sake of creating an example,
1. Frequency of occurrence on a scale 1-10, where 1 is rarely and 10 often (P1)
2. Severity of defect on a scale 1-10, where 1 is not severe and 10 is very severe (P2)
Time to make a table:
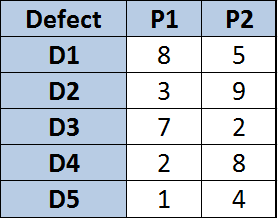 Defects with assigned properties P1 and P2
Defects with assigned properties P1 and P2
Ok, the values might not make so much sense but let’s ignore that for now. We have everything we need to calculate the distances. Note that all this assumes that the properties are numeric, if you have other properties such as “red” or “green” you need to decide how to calculate the distance between “red” and “green”. For numbers we use the Euclidean distance. I’m not going to go through all the boring details, but the distance table will look like:
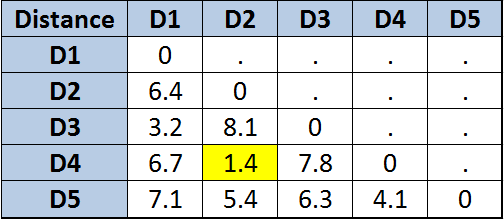 Distance table
Distance table
D2 and D4 are closer to each other – that is, more similar – than any other defects. Hence we cluster them in cluster A. And so it goes on. What we end up with is the following dendogram:
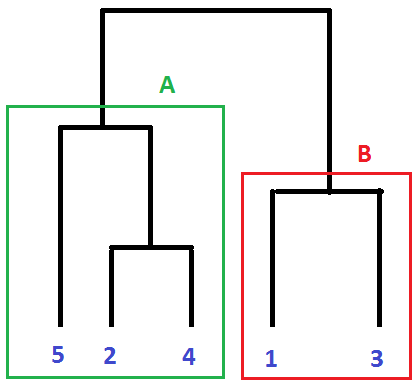 Dendogram. Defects are clustered based properties
Dendogram. Defects are clustered based properties
That’s it! Two important points here are i) you need a tool because you definitely do NOT want to do this by hand and ii) how about non-numeric properties, how do you measure distances? I definitely think dendograms can be useful, but a tool needs to be found and then there must be some thought on which properties to use – what kind of information do we want from the dendogram?
This post is just a collection of initial thoughts and is focused on what a dendogram is. I will now crawl back under the rock I came from and think more about how to actually use it for testing.

